Researching skin-colour prejudices and AI's potential for bias. To get to the bottom of this, we checked how our photo database is perceived by various AI engines, alongside several workshop participants and experts.

This project addresses two pressing contemporary issues: skin-colour prejudices and AI's potential for bias. It explores how skin colour is perceived through photography.
The project revolves around a series of photographs, in a sense a dataset, representing all skin types, which will be taken across the Netherlands, featuring diverse groups from amateur football club players to elderly immigrants. The diverse photographs will be combined in various ways using AI, and this project seeks to delve deeper into its applications and biases. While AI potentially offers many conveniences, its biases stemming from homogenous datasets can result in unintentional discrimination. Take a look at the preview below.
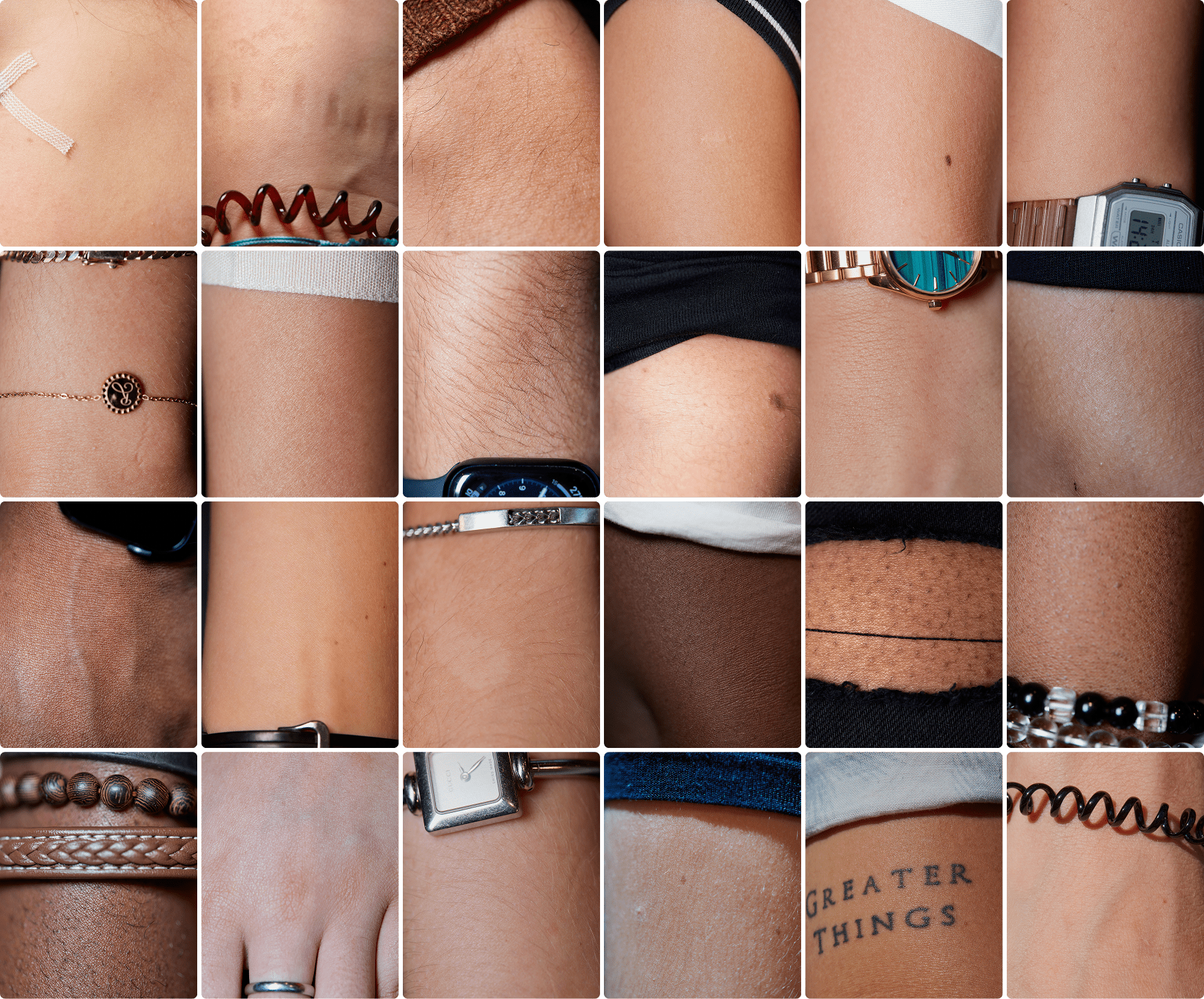
Seeking to eventually show the significance of the human factor in the process of image classification by AI, 3 major pillars were determined in the project.
Perform a research on which free AI engines are suitable for the COLOUR project. The criteria are:
Because of the increasing pace and digitalization of our everyday, we have to make decisions fast. When we do this, we don't notice things, we don't elaborate enough, we overlook. Inevitably, this data ends up in our computers and there ... well, that's where it makes a mess. Especially when we look at artificial intelligence, which, often treated as our salvation, is the most likely to adopt our biases. Because it works on the principle of machine learning, all the data it operates with, is what we, humans input into the system.
It could be compared to a child, who at some point reaches the splendor and wisdom of an adult. Although, in the meantime it adopts inappropriate traits, these for which we should be ashamed. The lack of sufficient quantity and variety of samples means that widely available AI tools at this stage cannot yet be trusted, and certainly not considered some absolute truth.
Giving our participants limited time to label images, we want to point out that humans usually don’t wait long to make their judgement. Why should we expect a computer to be more empathetic?
One of the first confrontations of our database with artificial intelligence took place on a platform called Clarifai. In simple terms, it allows users without programming skills to train their own prediction model or use those created by other users and the platform itself. Having around 80 pictures to test we decided to have them analyzed by an existing engine, trained and made available to use by Clarifai. With the name of the engine "general-image-recognition" we expected to get generic, neutral tags on our pictures. You can imagine what our surprise was when we received the following results:
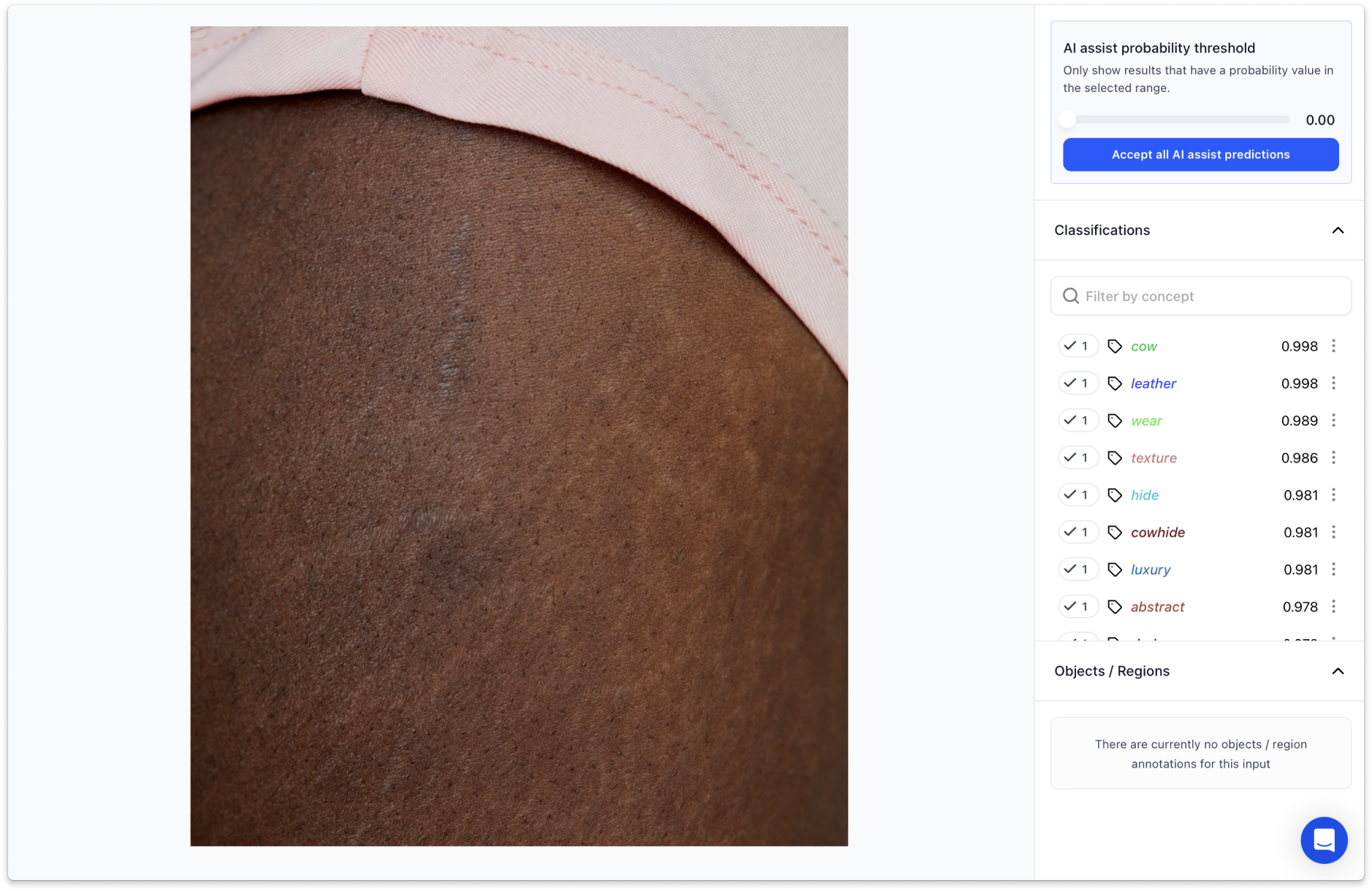
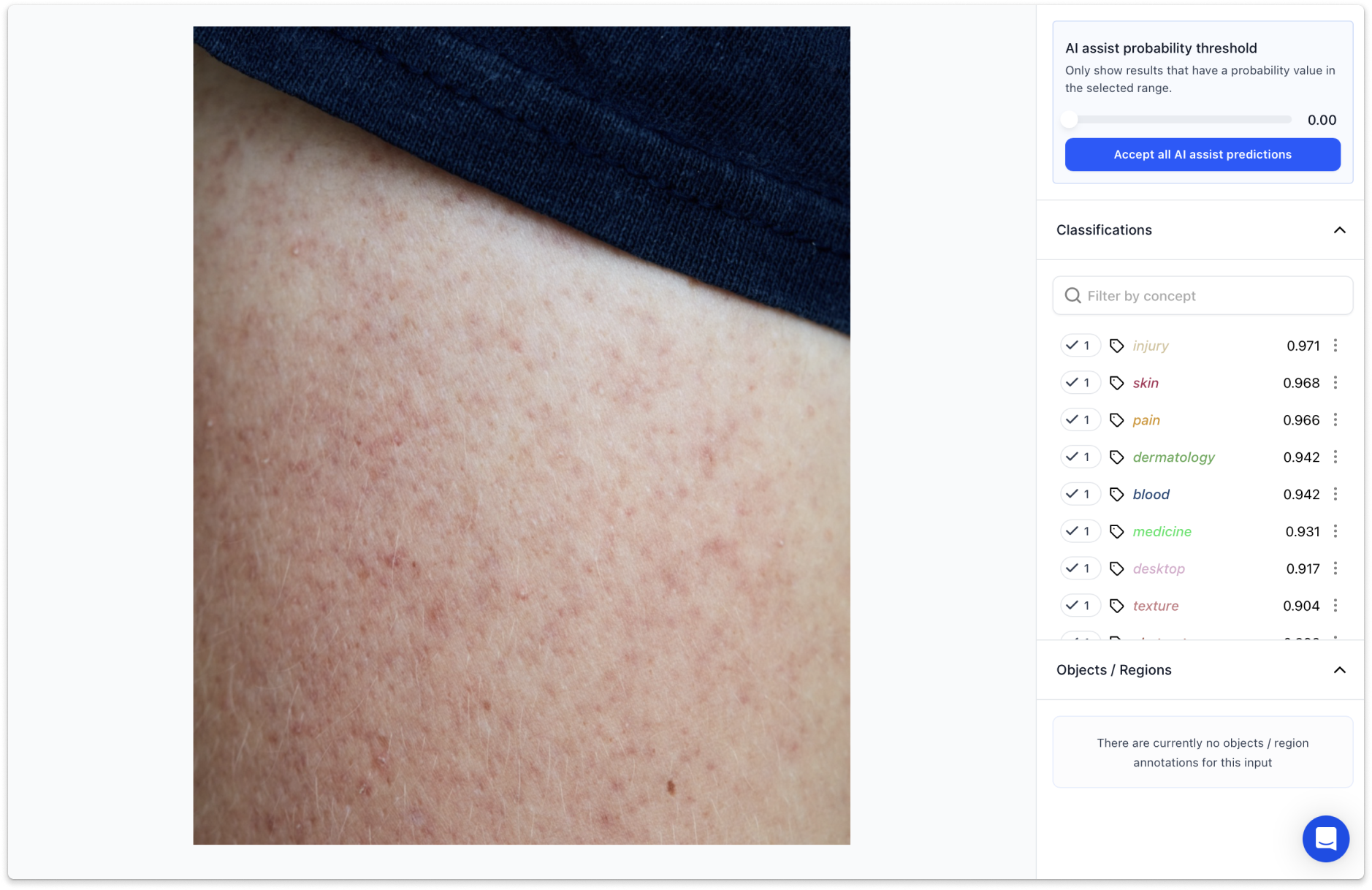
Tags like “injury” or “cowhide” next to regular pictures of human skin definitely gave us an idea of how biased can poorly trained model be. Increasing representativeness in datasets has to go along the fast-growing AI trend or mistakes like this will be happening more often. Due to the still relatively small base of photos, there is a lot of work ahead of us before we can train our own model. However, our main goal is to do it right and for this we need an inclusive and progressive database.
In order to increase social awareness and sensitivity, but also to gather data necessary for our AI training model, we held a series of workshops in which we asked participants to label the images from our database.

To point out how easy it is for our bias to slip to the computer world, we provided our participants with many images, and gave them very little time to label these. On the internet these conditions are common as everything happens really fast competing for our attention.

In the end of the workshop, we facilitated a conversation where everyone could speak their thoughts on the workshop, but also AI and prejudice in general.

We wanted to use these label to train our own AI image recognition model. However, we realized that after the first session of workshops we had way too many labels per every image. To successfully train a model we needed the opposite ratio - many images per every label. We addressed this issue in the next iteration.
During this workshop, we managed to reverse our methodology. We asked participants to match the provided images to labels which we placed on the walls.



The next step was to input all the data into the AI software. Since the data sample is still relatively small, we will not share the result of the model training.
I gained knowledge about AI models and engines, exploring how they work and differ in application. Additionally, I learned about effective workshop organization, from planning to facilitation, to ensure meaningful collaboration and outcomes. These skills broadened both my technical understanding of artificial intelligence and my ability to guide group processes.